최근 TAD는 엄청난 발전을 이루었으며 최근 TAD 연구는 end-to-end, scaling up 두가지에 집중하고 있습니다.
하지만 이러한 방법은 GPU 메모리에 의해 많은 제약을 받습니다.
또한 Backbone 전체를 fine-turning하는 것은 catastopic forgetting, Overfitting 등의 문제를 일으킵니다.
이러한 문제를 해결하기 위해 위 논문에서는 Adatad를 제안하였습니다.
Adatad는 Scaling up, E2E방식을 모두 결합하여 가장 높은 성능을 달성하였습니다. 또한 feature based 방식의 최고 성능을 뛰어넘었습니다
(1) E2E 방식의 도입 장점
1) Domain gap
E2E 방식을 통해 얻을 수 있는 가장 큰 장점은 Pretraining 단계와 Fine-tuning 단계의 task 차이를 완화해 준다는 것 입니다.
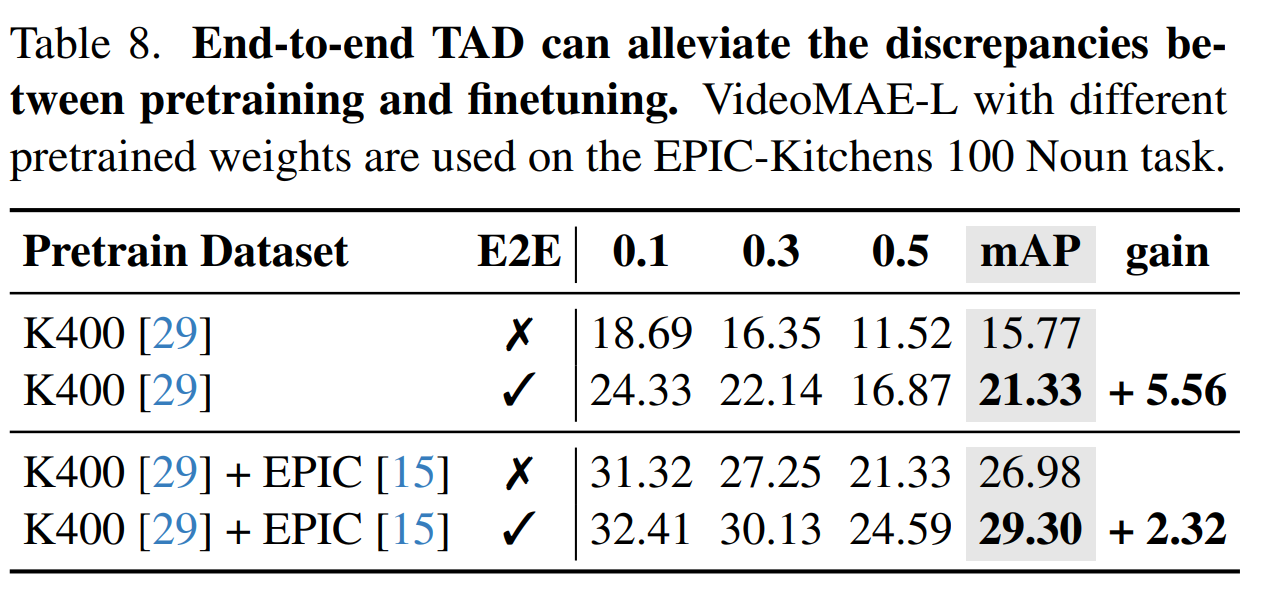
표 8에서 첫번째 칸은 Kinetics-400 데이터 셋으로 Backbone을 학습하고 EPIC-Kitchens 100 에 대한 Feature based 방식, E2E방식의 성능을 비교하였습니다.
이때 E2E 방식을 사용한 것은 Feature based 방식에 비해 5.56% 높은 mAP 성능을 보입니다.
E2E 방식을 통해 Data domain gap을 완화할 수 있다는 것을 알 수 있습니다.
2) Task gap
두번째 칸은 Kinetics-400 데이터 셋으로 사전학습하고 EPIC-Kitchens을 통해 추가학습한 Backbone을 사용하여 Feature based 방식, E2E방식의 성능을 비교한 결과입니다.
EPIC-Kitchens은 EPIC-Kitchens 100과 유사한 Domain을 가지며 이를 통해 도메인 차이를 줄여주었음에도 2.32% 성능이 상승하였습니다.
이를 통해 E2E는 data의 차이 뿐만 아닌 사전학습 단계의 Classification task와 Fine tuning 단계의 Localization task의 차이를 완화할 수있습니다.
또한 추가적으로 E2E 방식은 미리 비디오의 Feature을 추출해두는 Feature based 방식과 달리 Video spatial augmentation 방식을 사용하여 모델의 성능을 더욱 향상시킬 수 있습니다.
(2) scaling up 도입 장점
scaling up 방식은 input data 또는 Model의 사이즈를 키우는 것을 말합니다. 특히 videomae의 연구에 따르면 actionforemer 내부 backbone의 사이즈를 키웠을 때 mAP 성능이 10% 증가했다고 합니다
(3) 두 전략의 사용
직관적으로 위 두 방식을 함께 활용하면 TAD 성능을 크게 향상시킬 수 있을 것입니다.
하지만 위 두 전략은 상당한 GPU memory를 요구하고 작은 모델만을 사용하여 e2e를 진행하도록합니다.
또한 이전 e2e 방식은 backbone 전체를 fine tuning 하였습니다.
이 방식은 catastopic forgetting, Overfitting의 문제가 있습니다.
이러한 이유로 e2e가 feature based 방식(feature를 사전에 추출해둠)에 비해 더 좋은 장점을 가지고 있으나 낮은 성능을 기록하고 있었습니다.
(4) Method
1) Frame representation 방식

왼쪽은 frame representation 방식 오른쪽은 snippet representation 방식을 나타냅니다.
frame representation 방식에서 stride는 frame을 추출하기 위한 간격을 나타냅니다.
예를 들어 stride가 4라면 0,4,8,12, ~ , 4n 번의 frame만 비디오에서 추출합니다.
위와 같이 진행하고 만약 frame개수가 768개 이상이라면 비디오 편집 때의 잘라내기와 유사하게 무작위로 연속된 768개의 frame을 추출합니다.
Snippet representation 방식은 비디오를 일정한 길이로 나누어 여러개의 snippet / clip을 형성합니다.

표 1은 frame representation 방식과 snippet representation 방식에 대한 mAP 성능 및 Memory를 비교한 결과입니다.
feature extractor backbone이 freeze 되어 있을 경우 frame representation 방식은 snippet representation 방식에 비해 높은 성능을 기록하였으며 memory도 매우 적게 사용합니다.
E2E 방식일 경우 snippet representation 방식이 frame representation 방식에 1%정도 높은 성능을 보이는 것을 볼 수 있습니다. 하지만 snippet representation 방식은 frame representation 방식에 비해 memory를 8배이상 사용하는 것을 확인할 수 있습니다. 성능과 memory를 모두 살펴보았을 때 frame representaion 방식이 더욱 효율적이며 E2E 방식에 더욱 적합함을 알 수 있습니다.
2) Temporal informative Adapter(TIA)

위의 Tabel1을 보면 e2e 방식을 사용할 때 VideoMAE-S와 같이 작은 backbone만을 사용합니다.
만약 backbone의 크기를 키운다면 메모리는 그와 비례하게 증가할 것 입니다.
또한 Full fine tuning을 진행한다면 전이학습의 효율이 떨어지게 됩니다.
만약 downstream dataset의 다양성이 부족하다면 full fine tuning은 사전학습 모델이 가지고 있던 강력한 특징 representation 능력을 파괴할 수도 있습니다.
이 모듈은 이전의 adaptor와 다르게 temporal depth-wise convolution layers를 추가하였습니다.
temporal convolution을 통해 local informative context를 모으고 현재 시간에 대한 representaion 능력을 키우기 위해 추가하였습니다.
또한 마지막 up projection layer는 weight와 bias 가 0으로 초기화 되어 있습니다.
이를 통해 전이학습의 초기과정에서 backbone에 큰 영향을 끼치지 않도록 할 수 있습니다.

표 4는 feature based 방식, snippet representation 방식 , frame represetation 방식 , adatad 방식의 학습 파라미터 개수, Memory, mAP를 비교한 결과 입니다.
이때 snippet representation 방식 , frame represetation 방식 , Adatad방식은 E2E 방식을 사용합니다.
VideoMAE-S을 backbone으로 하였을 경우를 보시면 우선 E2E 방식이 feature based 방식에 비해 높은 성능을 기록하기 있음을 확인할 수 있습니다.
VideoMAE-L을 backbone으로 하였을 경우 snippet representation 방식을 사용한 경우 학습 parametor의 양은 3억개이며 193GB의 메모리를 차지합니다.
이에 반해 frame representaion 방식을 사용한 경우는 메우적은 13.1 기가의 메모리만을 사용합니다.
Adatad 방식을 적용한 경우 메모리는 11기가로 감소하고 학습 파라미터는 1/20 로 감소합니다. 또한 frame representation 방식만을 적용한 경우보다 mAP가 0.5 상승하였습니다.
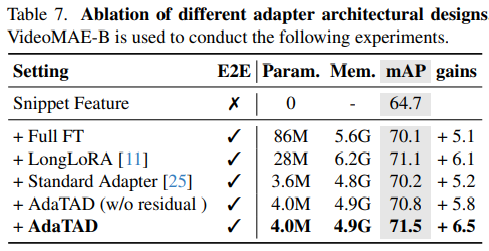
위 표는 Adaptor의 구조에 따른 성능 비교를 나타냅니다.
Adatad 방식은 full fine tuning 방식에 비해 매우 적은 parametor를 가지면서 standard adapter 보다 약간 많은 학습 paramerter를 가지지만 더욱 1.3 높은 mAP 성능을 가집니다.
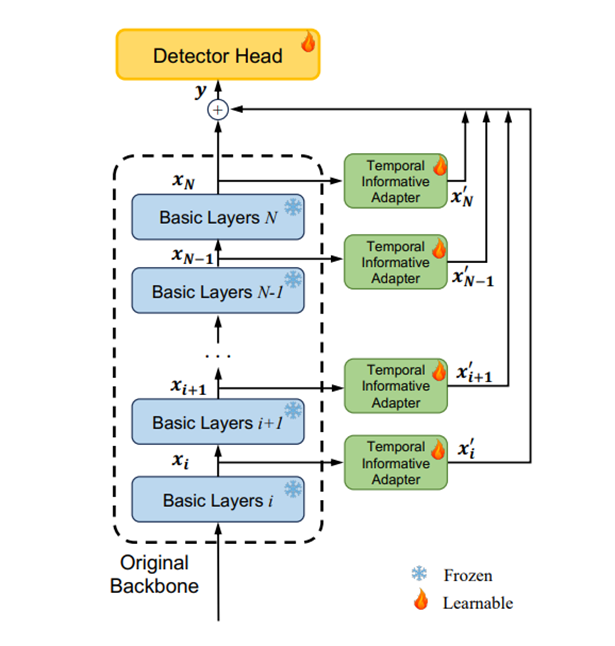
3) TIA를 Backbone과 병렬로 연결
위 논문에서 마지막으로 제안하는 방법은 TIA 모듈을 위 그림과 같이 병렬로 연결하는 것입니다.
TIA가 backbone내부의 연산에 기여하지 않도록하고 이를 통해 backbone 내부에 역전파가 진행되지 않아도 됩니다.
이를 통해 엄청난 memory 감소 효과를 누릴 수 있게됩니다.



