위 논문은 Test entropy minimization(Tent) 방식을 제안합니다.
(1) Fully Test-time adaptation
최근 Deep network는 큰 발전을 이루어왔고 Train data와 Test data의 Domain이 같을 경우 엄청난 성능을 보입니다.
하지만 Test data의 domain이 달라질 경우 모델의 성능은 크게 하락합니다.
이를 해결하기 위해 다양한 방법이 제안되었습니다.
기존 Domain Adaptaion 방식은 Source data와 Target data를 모두 활용하여 Target domain에 대한 adaptaion을 진행합니다.
또한 Test-time training은 Source data로 사전학습을 진행할 때 supervised loss, self-supervised loss를 모두 사용하여 진행합니다.
이를통해 Test 때 self-supervised loss를 통해 adaptaion을 더욱 안정적으로 진행할 수있습니다.
Fully Test-time adaptation 방식은 Source data의 필요없이 Label이 제공되지 않는 Target data로 adaptation을 진행하는 방식입니다.
Tent는 Fully Test-time adaptation을 위해 제안된 방법입니다.
(2) Entropy minimization

그림 1은 Model Predictions의 Entropy를 계산하고 이에 대한 Error를 정리한 그래프입니다.
그래프에서 쉽게 알수 있듯이 Entropy가 상승할수록 이에따라 Error가 증가하는 것을 알 수 있습니다.
그림 2는 corruption Lever에 따라 Loss, Entropy를 측정한 결과입니다.
Loss와 Entroy 모두 Corruption Level에 따라 증가하는 것을 확인할 수 있습니다.
Tent는 Test 때 모델이 출력한 Prediction에 대해 Entropy loss를 계산하고 이를 최소화하는 방식으로 학습을 진행합니다.
(3) MODULATION PARAMETERS

Tent는 모델의 모든 파라미터를 업데이트 하는 것이 매우 비효율적이라고 말합니다.
모델은 Source data를 학습하였으며 모든 파라미트를 업데이트 하는 것은 모델의 파라이터가 기존 정보를 잃어버릴 수도 있습니다.
또한 모델은 비선형적이며 모델 내부 파라미터는 고차원적이기 때문에 Optimization 을 진행할 때 매우 민감하게 반응하며 비효율적일 수 있습니다.
이에 Tent는 안정성과 효율성을 위해 Normalization layers를 업데이트 합니다.
Forward 단계에서 각 Layer의 Normalization statistics(평균, 분산)을 추정하고 Prediction에 대한 Entropy loss를 계산합니다.
Backward에서 Transformation parameters를 업데이트 합니다.
(4) 결과
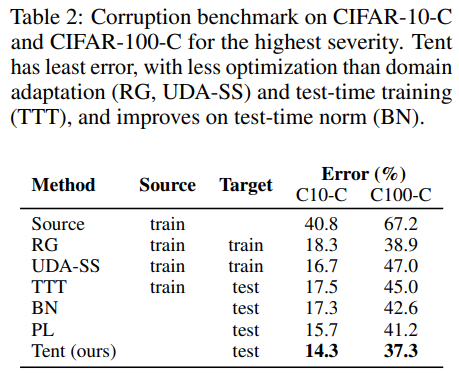
Tabel 2 는 ResNet26을 사용하여 CIFAR-10-C, CIFAR-100-C에 대하여 각 방법의 성능을 평가한 결과입니다.
Tent는 과거의 모든 방법에 대해 가장 좋은 성능을 보였습니다.
또한 Source data를 추가로 활용한 방법보다도 더욱 좋은 성능을 기록하였습니다.
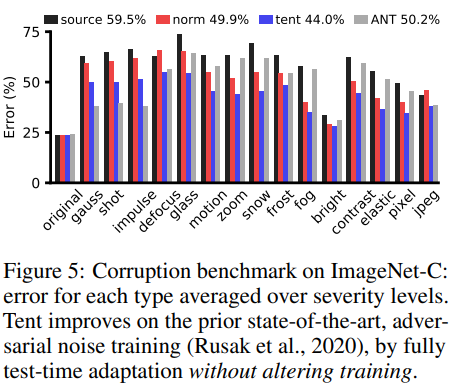
그림 5 는 ResNet50을 사용하여 ImageNet-C에 대해 Corruption 종류별로 Norm, ANT, Tent의 성능을 평가한 결과입니다.
Tent는 모든 Corruption 종류에 대해 Source 모델보다 성능이 상승하였습니다.



