위 논문은 Test-Time Zero-Shot Temporal Action Localization 방식을 처음 제안한 논문 입니다.
우선 Zero-Shot Temporal Action Localization(ZS-TAL)은 training time에 보지 못한 action class에 대해서도 test time에 모델이 예측을 할 수 있도록 하는 것이 목표입니다.
(1) 배경
최근 개발된 Vision language model은 웹에서 추출한 방대한 데이터 셋을 학습하여 일반화 능력이 뛰어납니다.
또한 전통적인 이미지 분류 모델의 성능을 뛰어넘기도 하였습니다.
하지만 Video domain에 적용하여 활용할 경우 image와 video의 구조적인 차이에 의해 추가적인 fine-tuning이 필수적으로 요구되며 이는 모델의 generalization capability를 낮추게 됩니다.

위 그래프는 EffPrompt와 STALE의 성능을 in-distribution과 out-of-distribution에서 측정한 결과입니다.
쉽게 설명하며 초록색의 Training 과 Test를 동일한 데이테 셋에 대해 진행한 결과이고 보라색의 경우는 Training 때의 데이터 셋과 Test 때의 데이터 셋이 다른 경우입니다.
두 모델 모두 out-of-distribution에 대한 성능이 현저히 떨어지며 이는 fine-tuning을 진행함으로써 모델의 generalization capability가 낮아지는 것을 나타냅니다.
(2) 제안하는 방법
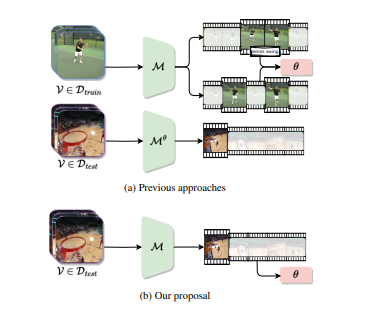
기존의 모델은 training data를 사용하여 모델의 파라미터를 업데이트하고, 모델의 파라미터를 고정한 후 test data에 대한 평가를 진행합니다.
하지만 위 방법은 모델의 generalization capability가 낮아지는 단점이 있기 때문에 이 논문의 저자는 training data가 없는 상황을 가정하여 모델을 개발합니다.
이 논문의 저자들이 제안한 방식은 Test Time Adaptation for Temporal Action Localization(T3AL)이며 이 방식은 Test data를 사용하여 모델의 파라미터를 업데이트하고, 모델을 평가하는 방식입니다.
T3AL 은 3가지 단계로 구성되어 있습니다.
1) Video-level pseudo-labelling

Video-level pseudo-labelling 단계는 Video-level pseudo-label을 생성하는 단계이며 아래 순서로 진행됩니다.
1. 모든 frame을 vision encoder, projector에 입력하고 Frame level representation을 추출하고 평균냅니다.
2. Textual Class Name을 Language encoder, projector에 입력하고 각각에 대한 representation을 추출해 냅니다.
3. Frame level representation의 평균과 Textual Class Name에 대한 representaion의 cosine 유사도를 계산하고 가장 높은 유사도를 보이는 Textual Class Name이 pseudo-label로 선택됩니다.
2) Self-supervised prediction refinement

Self-supervised prediction refinement는 Proposal 생성을 위해 Coarse-grained video prediction 정제하는 과정이며 아래 순서로 진행됩니다.
1. 모든 frame을 vision encoder, projector에 입력하고 Frame level representation을 추출하고 평균냅니다.
2. Video-level pseudo-labelling 단계에서 생성한 pseudo label의 Textual Class Name을 Language encoder, projector에 입력하고 representation을 추출해 냅니다. (편하게 class representation 이라 하겠습니다.)
3. class representation과 모든 Frame level representation의 cosine 유사도를 계산합니다.
4. consine 유사도가 높은 상위 n개의 Frame level representation을 positive sample로 구성하고, consine 유사도가 낮은 하위 n개의 Frame level representation을 negotive samlpe로 구성합니다.
5. 이후 이 두 종류의 sample을 통해 Representation loss, Separation loss를 계산합니다.
+ Representation loss
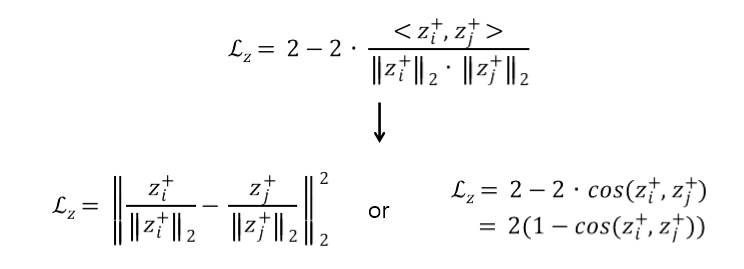
- 두 positive sample의 단위 벡터를 구하고 mean squared error(MSE)를 계산한 것입니다.
- 두 Positive sample이 유사한 값을 가지 도록 유도(Positive sample의 cosine similarity가 커지도록 유도) 합니다.
- Proposal 내부 Frame 간의 Semantic closeness가 높아지도록 유도합니다.
+ Separation loss

- s 벡터는 positive sample과 negotive sample의 score입니다.
- 각 score는 class representation과 consine 유사도를 계산한 값 입니다.
- b는 s에서 positive sample에 해당하는 위치를 1로, negotive sample에 해당하는 위치를 0으로 하여 새롭게 생성한 벡터입니다.
- Separation loss는 s, b의 MSE를 계산하며 이를 통해 Proposal 내부 Frame과 Preudo labe 의 Semantic closeness가 높아지도록 유도합니다.
3) Text-guided region suppression

부정확한 proposal을 제거하는 단계입니다.
1. proposal에 해당하는 frame에 대한 frame representaion을 모두 decoder에 입력해 주고 caption을 생성합니다.
2. caption을 language encoder에 입력해 주어 languge representaion을 추출하고 평균내어 d1, d2 .... 생성합니다.
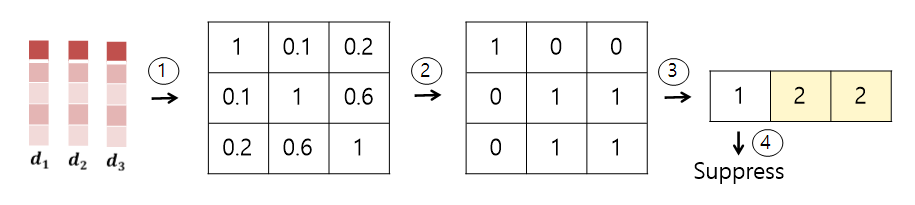
3. 모든 경우에 대해 cosine 유사도를 계산합니다.

4. 특정 Threshold에서 Binarize 진행 후 Column-wise Sum을 진행합니다.
5. Threshold 보다 작은 Score를 출력한 Proposal을 제거합니다.
간단히 정리하면 각 proposal의 Textual representaion을 생성하고 다른 proposal의 Textual representaion과유사도가 낮은 Proposal을 제거합니다.
(3) 결과
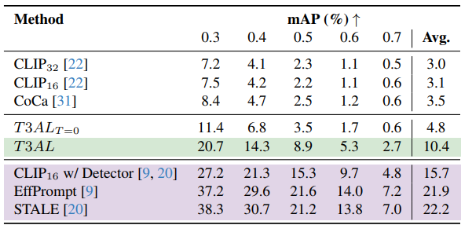
위 표는 다른 Training based 방식(보라색)과 성능 비교를 한 것 입니다.
T3AL은 Training data를 사용하지 않으므로 다른 방법에 비해 성능이 낮은 것을 확인할 수 있습니다.

위 그래프는 Oracle study를 통한 T3AL의 성장 가능성을 나타냅니다.
만약의 경우를 가정하고 실험을 진행하며 Pseudo label을 완벽하게 예측한 경우, 정확한 개수의 action region을 선택한 경우, positive sample과 negotive sample을 적절히 선택한 경우, 모든 경우를 정확히 해낸 경우를 실험합니다.
모든 경우를 정확히 해냈을 경우 성능은 22.6%까지 올라가며 training based 방식보다 높은 성능을 기록하게 됩니다.



