(1) 배경
labeled 데이터 셋을 형성하는 데에는 많은 시간과 노력이 들며 label에 대한 정보를 보안상의 이유로 얻지 못할 수도 있습니다.
labeled 데이터에 의존하지 않기 위해 다양한 연구가 진행되고 있으며, 이러한 연구의 일환인 semi-supervised learning은 labeled 데이터와 unlabeled 데이터를 함께 사용하여 모델학습을 진행하는 방식입니다.
이를 위해 semi-supervised learning은 labeled 데이터, unlabeled 데이터에 대해 각각 서로 다른 loss term를 사용하여 학습을 진행합니다.
주로 사용되는 semi-supervised learning 방식은 entropy minimization, consistency regularization, generic regularization 3가지로 분류됩니다.
Mixmatch는 위 3가지 대표적은 방식을 모두 사용하는 새로운 semi-supervised learning 방식을 제안합니다.
(2) 제안하는 방법

1) Data Augmentation
labeled examples에 대해서는 1개의 데이터에 대해 1가지 방법의 augmentation을 적용합니다.
unlabeled examples에 대해서는 1개의 데이터에 대해 K번 augmentation을 진행하여 K의 데이터를 새롭게 생성합니다.
이때 random horizontal flips, crops 등 표준적인 data augmentation방식을 사용합니다.

2) Label Guessing
unlabeled data에 대해 적용하는 방식이며 다음과 같은 순서로 진행됩니다.
1. 증강된 K개의 data를 모델에 입력하여 class distributions을 예측합니다.
2. 예측된 K개의 class distributions을 평균내어 K개의 data에 대한 Guessed label로 사용합니다.
3) Sharpening
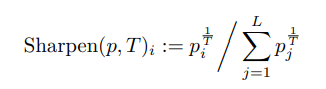
T는 "temperature"를 의미하여 p는 Guessed label 입니다.
temperature를 높일수록 Guessed label에 대한 entropy를 낮추어 주며 모델이 높은 confidence를 가지는 예측을 하도록 유도합니다.
4) Mixup
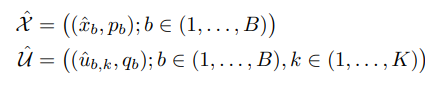
모든 과정을 완료하면 labeled data는 (augmented one example - one hot encoded label)을 pair로 batch 개수 만큼 존재합니다.
unlabeled data는 (augmented one example - guessed label)을 pair로 batch * k 개 만큼 존재합니다.
두 종류의 데이터를 shuffle하여 Mixup을 수행하기 위한 data source W를 생성합니다.
이후 labeled data 개수만큼 W에서 data를 추출해 Mixup을 진행하여 X'를 생성하고, 남은 W 내부 데이터를 가져와 unlabeled data와 mixup을 진행하여 U'를 생성합니다.
X'(labeled data)에 대한 모델 예측값에 대해서는 cross-entropy loss를 계산하고 U'(unlabeled data)에 대한 모델 예측값에 대해서는 L2 loss를 계산합니다.
(3) 실험 결과
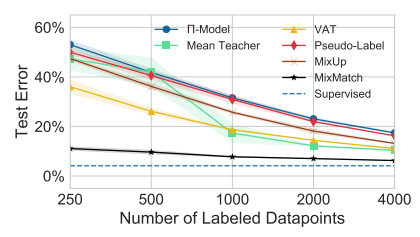
위 그래프는 CIFAR-10 데이터 셋에서 labeled data를 증가시키며 MixMatch와 기존 semi-supervised learning 모델의 성능을 평가한 결과 입니다.
MixMatch 방식이 기존 방식에 비해 가장 낮은 Error rate를 보이며, supervised 방식과 비교해서도 거의 유사한 Error rate를 보입니다.
(4) 결론
MixMatch는 기존의 semi-supervised learning에서 주로 사용되는 entropy minimization, consistency regularization, generic regularization 3가지 방식을 혼합하여 새로운 semi-supervised learning 방식을 제안하였습니다.



