(1) 배경
- semi-supervised learning(SSL)은 labeled data, unlabeled data를 모두 사용하여, 생성을 위해 상당한 노동력이 드는 labeled data에 대한 의존을 줄이기 위한 방식
- 이전 SSL을 위한 방식은 매우 복잡한 구조를 가짐
- FixMatch는 기존 SSL의 방식을 융합해 구조를 단순화하였고, 이를 통해 state-of-the-art를 달성(Consistency regularization, Pseudo-labeling)
- FixMatch의 단순함으로 인해 다양한 ablation study를 통해 FixMatch가 높은 성능을 달성할 수 있었던 다양한 factor에 대해 연구
(2) 방법

1) supervised Loss
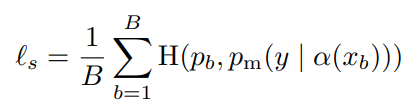
- weakly augmentation을 적용하여 labeled examples에 대한 예측 진행
- 기본 cross-entropy loss 사용
2) Unsupervised Loss

-과정-
1. weakly augmentation을 적용하여 unlabeled examples에 대한 pseudo label 생성
2. pseudo label의 confidence score가 threshold보다 높을 경우 pseudo label(hard)로 사용
=> hard label을 통해 unlabeled examples에 대한 예측이 작은 entropy를 가지도록 유도
3. pseudo label이 존재하는 unlabeled examples에 대해 strong augmentation을 적용하여 예측 진행
4. 기본 cross-entropy loss 사용
-주요사항-
- weakly augmentation을 적용한 경우, stong augmentation을 적용한 경우 모두 동일한 예측을 하도록 해 consistency regularization 적용
- 기존 consistency regularization 방식은 학습을 진행하며 Unsupervised loss에 대한 가중치를 점차 늘려나감
- FixMatch는 학습이 진행될수록 pseudo label의 confidence score가 threshold보다 높은 경우가 증가해 자연스럽게 Unsupervised Loss의 영향력이 확대됨
(3) 실험 결과
1) 다른 방법과의 비교
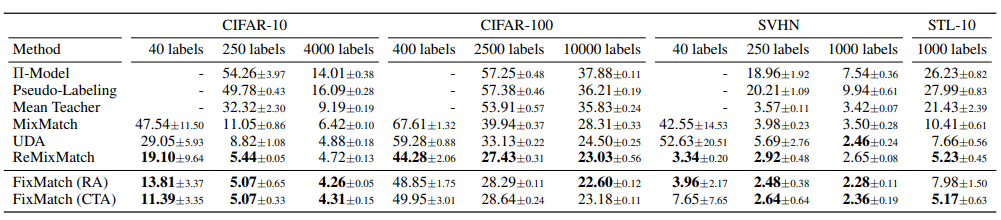
- 대부분 기존 방법에 비해 높은 성능을 달성
- Remixmatch는 Distribution Alignment를 통해 unlabeled set이 labeled set과 class distribution이 일치되도록 유하며 Fixmatch에 적용할 경우 Remixmatch보다 높은 성능 달성
2) labeled data 선택의 중요성

- labeled samples가 적을 경우 labeled samples의 quality에 따라 성능 차이가 크게 나타남
=> quality가 좋은 labeled samples를 선택한다면 매우 적은 label을 통해서도 높은 성능을 달성할 수 있음
3) Ablation Study
-Sharpening and Thresholding-
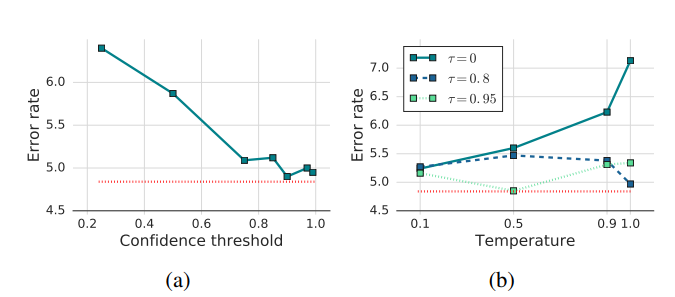
(a) - threshold의 크기에 따라 성능이 증가, threshold가 높은 경우 threshold를 약간 변형해도 성능이 큰 차이를 보이지 않음
(a) - threshold가 증가할 수록 pseudo label을 사용할 수 있는 경우가 줄어듬 => 성능은 증가하고 pseudo label은 양보다 질이 중요한 것을 증명
(b) - confidence threshold를 사용할 경우 sharpening에 의한 성능 폭은 매우 작음, confidence threshold를 사용하지 않을 경우 sharpening은 중요한 역활을 함
(b) - pseudo labeling을 thresholding, sharpening으로 교체하는 것은 매우 비효율적임
-Augmentation Strategy-
- pseudo label 생성시 strong augmentation을 사용할 경우 => 모델 학습 불가
- pseudo label 생성시 augmentation을 적용하지 않을 경우 => pseudo label에 overfit
- 모델 예측시 strong augmentation을 weakly augmentation을 교체한 경우 => 모델 학습이 불안정해지며 결국 붕괴됨
(4) 결론
- 기존 SSL 방법이 발전하면서 매우 복잡해졌으나 FixMatch는 구조를 단순화하였고, state-of-the-art 달성
- 구조 단순화를 통해 FixMatch의 작동방식을 섬세하게 연구할 수 있었음



