(1) 배경
- Video activity localization은 길고 편집되지 않은 video를 의미론적으로 이해하고, 원하는 action을 찾는 것이 목표임
- Action의 경계를 정확히 학습하는 것은 매우 어려움
=> Action은 시간에 따라 지속적으로 변화
=> Action이 변화할 때 확실한 변화 지점을 정의하기 어려움
=> Action의 경계를 정의하는 것은 주관적임
(2) 방법
!! DenoiseLoc는 Video activity localization problem을 Denoising 관점에서 접근 !!

1) Encoder
- Encoder는 input의 sementic information을 추출하기 위한 것
=> 서로 다른 양식의 데이터인 언어, 영상등에서 추출한 feature의 상호 관계 파악
=> long-term temporal dependency
- video snippet feature를 입력받으며 필요시 language token feature를 입력받고 최종 feature(memory) 출력
2) Decoder

-Self Attention-
- Proposal embedding에 대해 적용하였으며 다른 proposal 과의 관계성을 모델링하기 위해 도입
-Align1D-
- ROI Align을 통해 proposal의 start/end time을 기점으로 proposal feature 추출
- 입력은 GT noise spans, learnable spans, memory 임
- GT noise spans 생성 과정
1. Noise vector를 Query 개수만큼 생성
2. GT에 Noise vector를 더해 positive noise span 생성
3. ts_neg, te_neg 에 Noise vector를 더해 negotive noise span 생성
=> negotive noise span은 positive set과 GT를 공유
=> DINO 논문에서 negotive noise GT에 대해 denoising을 진행하고, 이에 대한 결과로 no object를 예측하도록 함
=> DINO 논문에서 positive noise GT에 대해 denoising을 진행하고, 이에 대한 결과로 class score, bounding box를 예측하도록 함
=> 위 과정을 통해 같은 action에 대해 유사한 proposal 예측을 출력하여도 더욱 정확한 proposal을 선택할 수 있도록함
- Dynamic Convolution-
- proposal embedding(learnable embedding) 과 Memory간의 상호작용을 모델링함
- 효과가 거의 없는 bins를 정제하고 최종 출력을 냄
(3) 실험 결과
1) 다른 방법과의 비교

- QVHighlights dataset에서 기존 방법에 비해 상당히 높은 성능 기록
2) Ablation Study
- Query 개수에 따른 성능 비교-
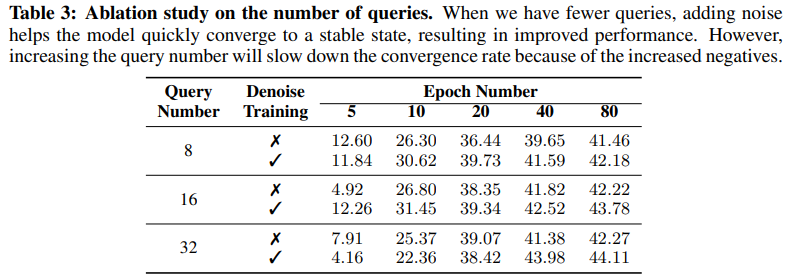
- Denoising training 을 추가하였을 경우 모델은 더욱 빨리 수렴하고 안정적으로 학습됨
- Query개수가 증가하면 모델은 더욱 빨린 수렴하고 높은 성능을 기록
- 특정 threshold 이상 Query개수를 늘리면 모델의 수렴 속도가 늦고 성능 하락
=> Query개수가 증가할수록 negotive set의 개수가 증가하기 때문
-Noise level에 따른 성능 비교-

- Noise level이 너무 작은 경우 오버핏팅 발생
- Noise level이 너무 큰 경우 언더핏팅 발생
- Self Attention, Dynamic Convolution의 영향-

- Self Attention, Dynamic Convolution을 통해 모두 모델의 성능을 상승시킴
- Self Attention을 통한 proposal-proposal interaction이 매우 중요함을 알 수 있음
- Dynamic Convolution을 통해 가장 많은 성능 상승을 이룸
=> proposals 경계를 진동시켜 target domain에 대한 augmentation을 진행, Dynamic Convolutions는 temporal feature에 민감함
(4) 결론
- Action의 경계를 정확히 학습하는 것은 매우 어렵기 때문에 DenoiseLoc는 Video activity localization problem을 Denoising 관점에서 접근
- Denoising training은 action proposal을 진동시켜 augmentation 효과를 냄
- 초기 Noise span을 통해 보다 의미있는 action boundary를 예측할 수 있도록 하였고 SOTA 달성
.
ROI Align 논문
https://arxiv.org/abs/1703.06870
Mask R-CNN
We present a conceptually simple, flexible, and general framework for object instance segmentation. Our approach efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. The method, called
arxiv.org
ROI Align 블로그
Understanding Region of Interest — (RoI Align and RoI Warp)
Visual explanation of how RoI Align works and why is it better than standard RoI Pooling?
towardsdatascience.com
DINO
https://arxiv.org/abs/2203.03605
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
We present DINO (\textbf{D}ETR with \textbf{I}mproved de\textbf{N}oising anch\textbf{O}r boxes), a state-of-the-art end-to-end object detector. % in this paper. DINO improves over previous DETR-like models in performance and efficiency by using a contrasti
arxiv.org



