https://arxiv.org/abs/2409.15264
UDA-Bench: Revisiting Common Assumptions in Unsupervised Domain Adaptation Using a Standardized Framework
In this work, we take a deeper look into the diverse factors that influence the efficacy of modern unsupervised domain adaptation (UDA) methods using a large-scale, controlled empirical study. To facilitate our analysis, we first develop UDA-Bench, a novel
arxiv.org
(1) 배경
- UDA 는 target domain의 unlabeled dataset을 사용하며, 다른 source domain의 labeled dataset을 사용할 수 있는 방법임
- 최근 UDA 연구는 새로운 algorithms나 loss function 개발에 집중하는 반면 실제 domain adaptation 성능에 영향을 미치는 assumptions 에 대한 전반적인 이해는 부족함
--> 잠재적으로 UDA에 가장 높은 영향을 미치는 Backbone architectures, Unlabeled data quantity, Pretraining dataset 3가지 Factor에 대해 연구
--> initialization, learning algorithm, batch sizes등 실제 adaptaion과 관련없는 factor를 표준화하고, 여러가지 UDA 방법을 하나의 platform으로 통합함
(2) 연구 결과
1) The Need for UDA-Bench Framework
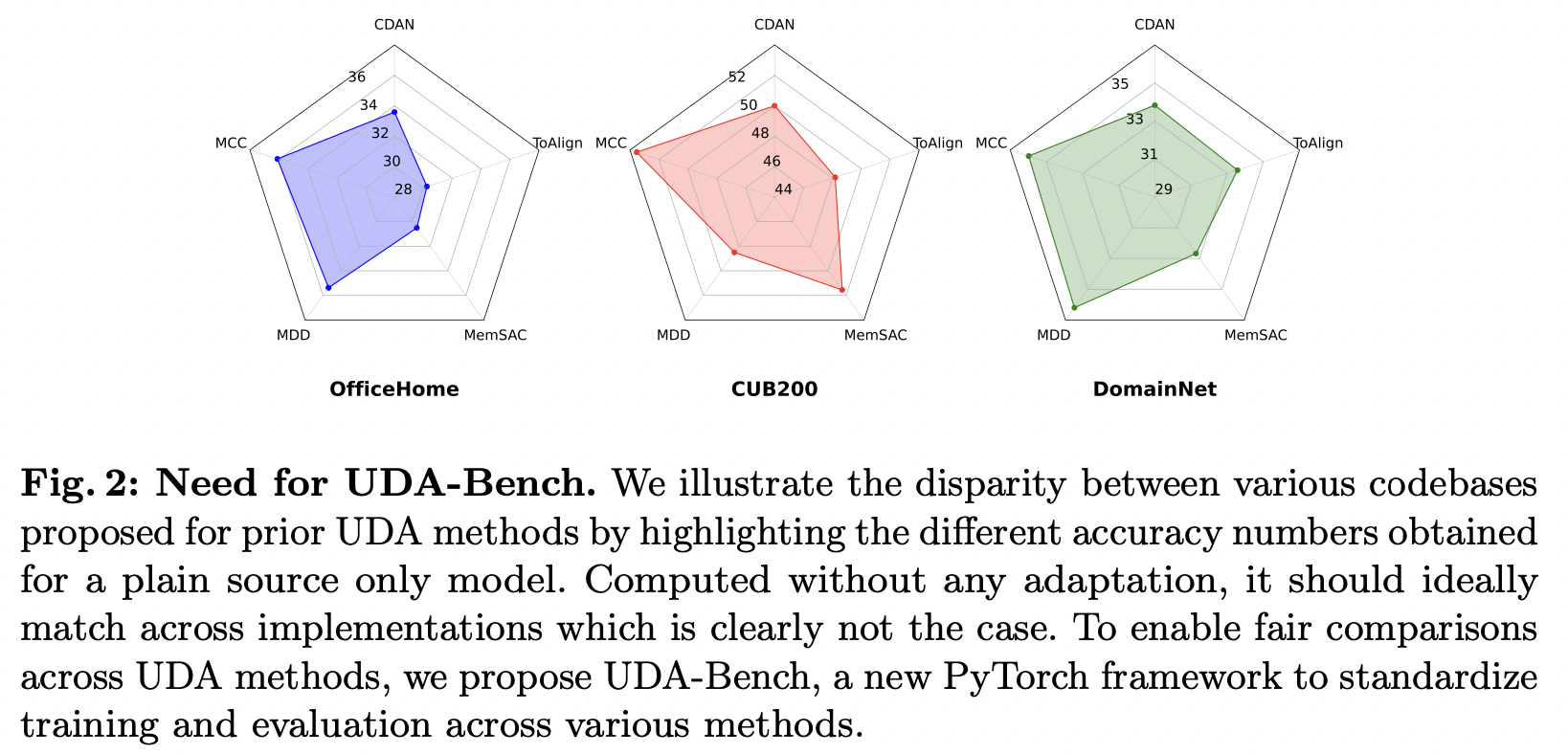
- 그림 2은 Adaptaion 관련 Loss를 모두 비활성화하고, source data에서만 UDA 를 진행했을 때 성능을 보여줌
- Adaptation 관련 Loss를 모두 제거하였으므로 모두 동일한 성능을 보여야 함
- deeper MLP as a classifier, batchnorm layers in the bottleneck layer, 10-crop evaluation and AdaMatch 등 각 방법의 학습 전력 차이 발생 (실제 adaptaion 방법과는 무관)으로 성능이 서로 다름
--> UDA-Bench Framework가 필요함
2) Which backbone architectures suit UDA best?

* Newer Architectures Show Better Domain Transfer
- Vision transformer 기반 모델이 가장적은 relative drop을 보임(Swin-V2-t)
- Swin-V2-t는 DomainNet(r->c)에서 ResNet-50을 통해 Domain Adaptation을 진행한 경우보다 높은 성능을 보임
-> complex adaptation algorithm을 사용하는 것보다 더욱 좋은 Backbone을 사용하는 것이 더욱 효과적일 수 있음
- Vision transformer의 Robustness는 이미 널리 알려져 있으며, 이것이 out-of-domain robustness로도 이어짐을 확인
- 데이터셋에 따라 모델의 relative ranking이 달라짐 -> Domain transfer의 type은 domain robustness에 영향을 미침

* UDA Gains Diminish With Newer Architectures
- 그림 3은 UDA를 진행했을 때 성능 증가 정도를 UDA method,Backone, 데이터 셋 별로 정리해 둠
- 더욱 좋은 out-of-domain robustness를 보이는 모델을 사용할수록 relative gain은 감소
- 가장 좋은 Adaptation method, Backbone은 dataset에 따라 모두 다름
- > 각 방법의 성능 비교전 backbone, architecture를 표준화 하는 것은 매우 중요함
3) How much unlabeled data can UDA methods use?

* UDA Accuracy Does Not Increase With More Unlabeled Data
- Domain transfer type에 무관하게 unsupervised adaptation은 unlabeled data에 대해 상당히 빠른 속도로 saturate 됨
-> 대략 25%의 unlabeled data를 사용했을 때부터 saturate, 100% 활용했을 때와 성능 차이가 매우 적음(1% 정도)
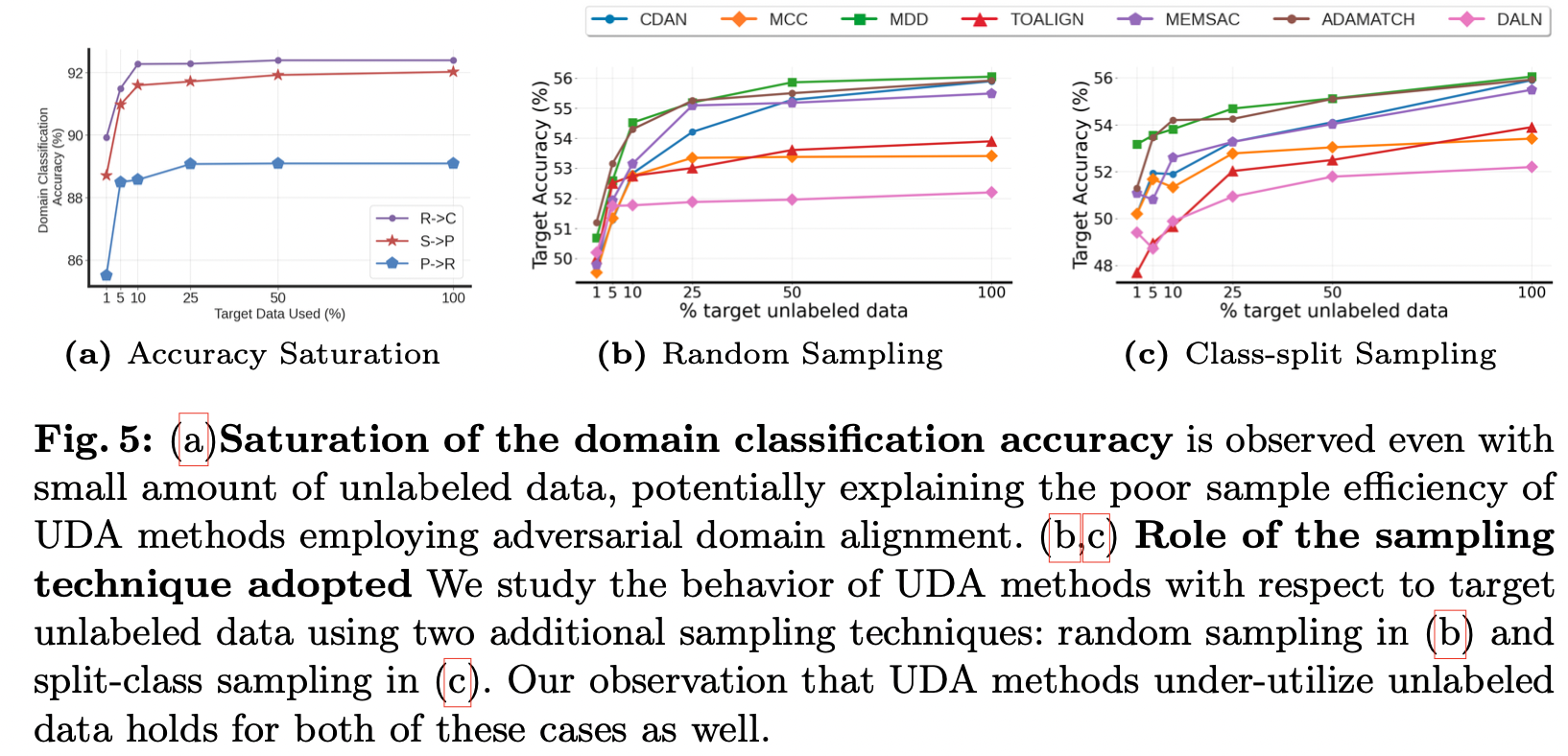
* Investigating Poor Data Efficiency of UDA Methods
- poor unlabeled sample efficiency는 adaptation objective를 통한 것으로 가정
- target unlabeled data에 대한 정확도를 측정 -> 25%의 데이터를 사용해서도 이미 정확도는 saturate됨
- adaptation accuracy의 saturation은 adaptation objective에 의한 것으로 확인
- 위의 관찰 결과는 여러 UDA 방법의 근간이 되는 Ben-David 등의 domain adaptation theoretical framework
와 대조를 이룸 (target unlabeled data가 많을 수록 target data에 대한 성능 증가)
4) Does pre-training data matter in UDA?

* Supervised Pre-training Using In-Task Data Helps UDA
- 포괄적으로 in-task pre-training은 downstream adaptation에 긍정적인 영향을 미침
- 사전학습 시 사용한 dataset에 따라 target domain에 대한 정확도 변화
- in-task data에 대한 pre-training은 더 관련성 있는 특성을 사전에 생성하여 유사한 downstream dataset에 대한 generalization 능력을 향상 시키는 것으로 가정
-> target unlabeled data가 주어졌을 때 적절한 pre-trained 모델 선택은 target domain에 대한 정확도를 향상하기 위한 좋은 방법임
* In-Task Pre-training is complementary to UDA method
- no adapt, IN-1M , CUB 에서 50.30이지만 adaptation(ToAlign)을 통해 12% 성능 증가, backbone(NAT-1M)을 교체해서 5% 성능 증가
- UDA 방법이 adaptation 데이터셋과 관계없이 기본적으로 ImageNet 을 사용
- GeoP, CUB에서는 PL-1M, NAT-1M을 통한 사전학습 모델을 사용하는 것이 좋음
-> target task에 맞추어 사전학습 모델을 선택하여 target에 대한 성능향상을 이끌어 낼 수 있음

* Nature of Pre-training Images matter for Self-supervised Learning
- Self-supervised Learning은 label 정보 부족으로 인해 Supervised Learning에 비해 적은 object semantics를 학습함
- IN-1M 에 대해 DNet, CUB에서(object-centric), PL-1M 에 대해 GeoP에서(scene-centric) benefit을 얻음
- self-supervised learning때 데이터셋의 이미지 특성(object-centric, scene-centric)은 downstream transfer에 큰 영향을 미침
*즉 supervised pre-trianed 모델을 선택할 때 task, self-supervised pre-trianed 모델을 선택할 때 Nature이 중요함*
(3) 요약
- Unsupervised domain adaptation의 성능에 영향을 미치는 Factor에 대해 연구
- Backbone architectures, Unlabeled data quantity, Pretraining dataset 3가지 Factor에 대해 연구
- 1) Advanced backbone을 사용할 때 UAD 효과 감소, 2)최신 UDA 방식은 Unlabeled dataset을 충분히 이용하지 못함, 3)Pretraining dataset은 추후 adaptation에 큰 영향을 줌 을 밝혀냄



