https://arxiv.org/abs/2203.11819
A Broad Study of Pre-training for Domain Generalization and Adaptation
Deep models must learn robust and transferable representations in order to perform well on new domains. While domain transfer methods (e.g., domain adaptation, domain generalization) have been proposed to learn transferable representations across domains,
arxiv.org
(1) 배경
- Domain transfer method는 주로 ResNet을 backbone으로 사용함
- Domain transfer method는 pre-training, transfer 단계로 이루어졌으며 전자에는 적게 관심을 가지고 있음
- modern large-scale pre-training이 Domain transfer에 큰 영향을 미침 -> 최신 SOTA backbone을 사용하여 Domain transfer 방법의 성능을 능가함
--> Domain adaptation, generalization에 pre-training이 미치는 영향을 network architectures, size, pre-training loss, and datasets 측면에서 연구
(2) 연구 결과
1) Single Source Domain Generalization
* Analysis of Network Architectures
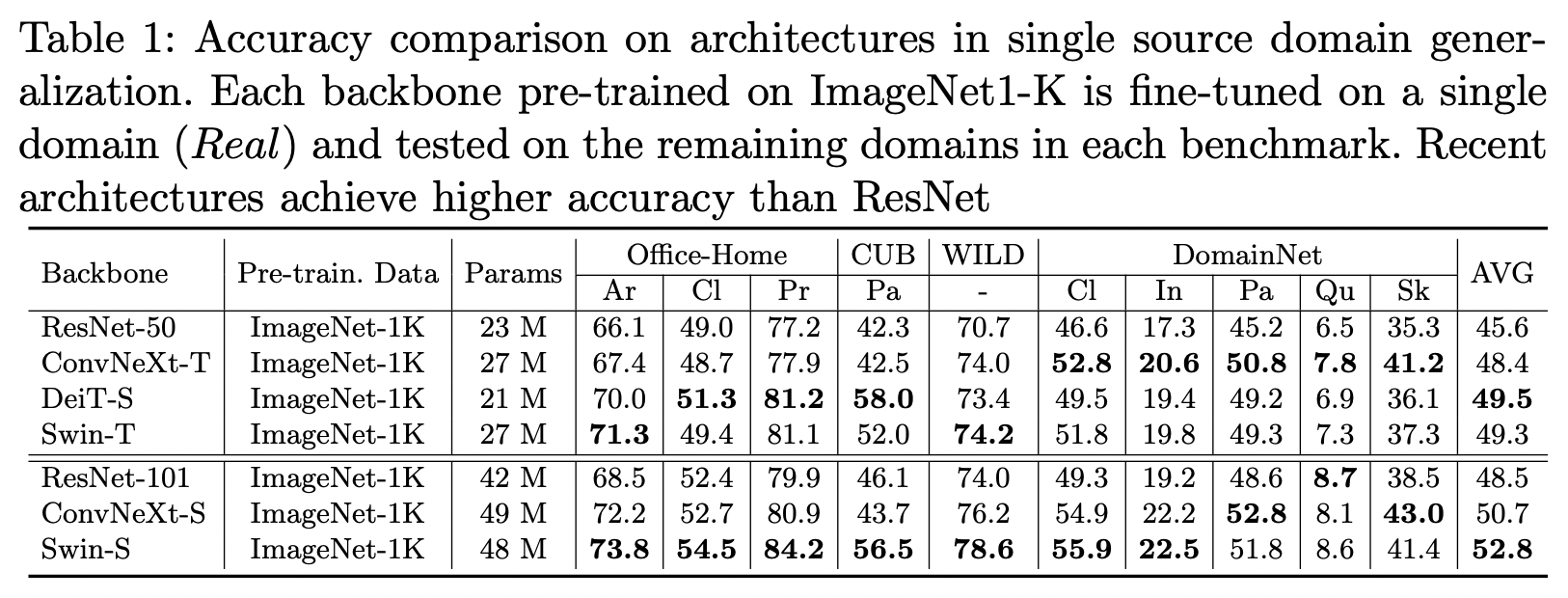
- Convnext, Transformer 기반 모델이 ResNet 성능을 뛰어넘음
- Transformer 기반 모델이 Office-Home, CUB, WILD에서 높은 성능을 보이나 CNN 기반 모델이 DomainNet에서 높은 성능을 보임
- Transformer, CNN은 서로 다른 Domain shift에서 robust함
* Analysis of Pre-training Datasets

- (a) ImageNet-22K를 사용한 경우 ImageNet-1K를 통해 사전학습한 경우보다 높은 성능을 보임
- (b) JFT-300M을 사용한 경우 ImageNet-22K를 사용한 경우보다 성능 상승이 적음 -> self-training이 사용되었기 때문
- (c) ALBEF를 사용한 경우 CUB에서 성능 하락을 보이지만 DomainNet에서 가장 큰 성능 상승을 보임
-> 더욱 많은 데이터 셋을 사용하는 것은 성능에 좋은 영향을 미침
-> 데이터에 따른 성능 상승은 사전학습 데이터와 downstream task에 큰 영향을 받음
* Analysis of Network Depth
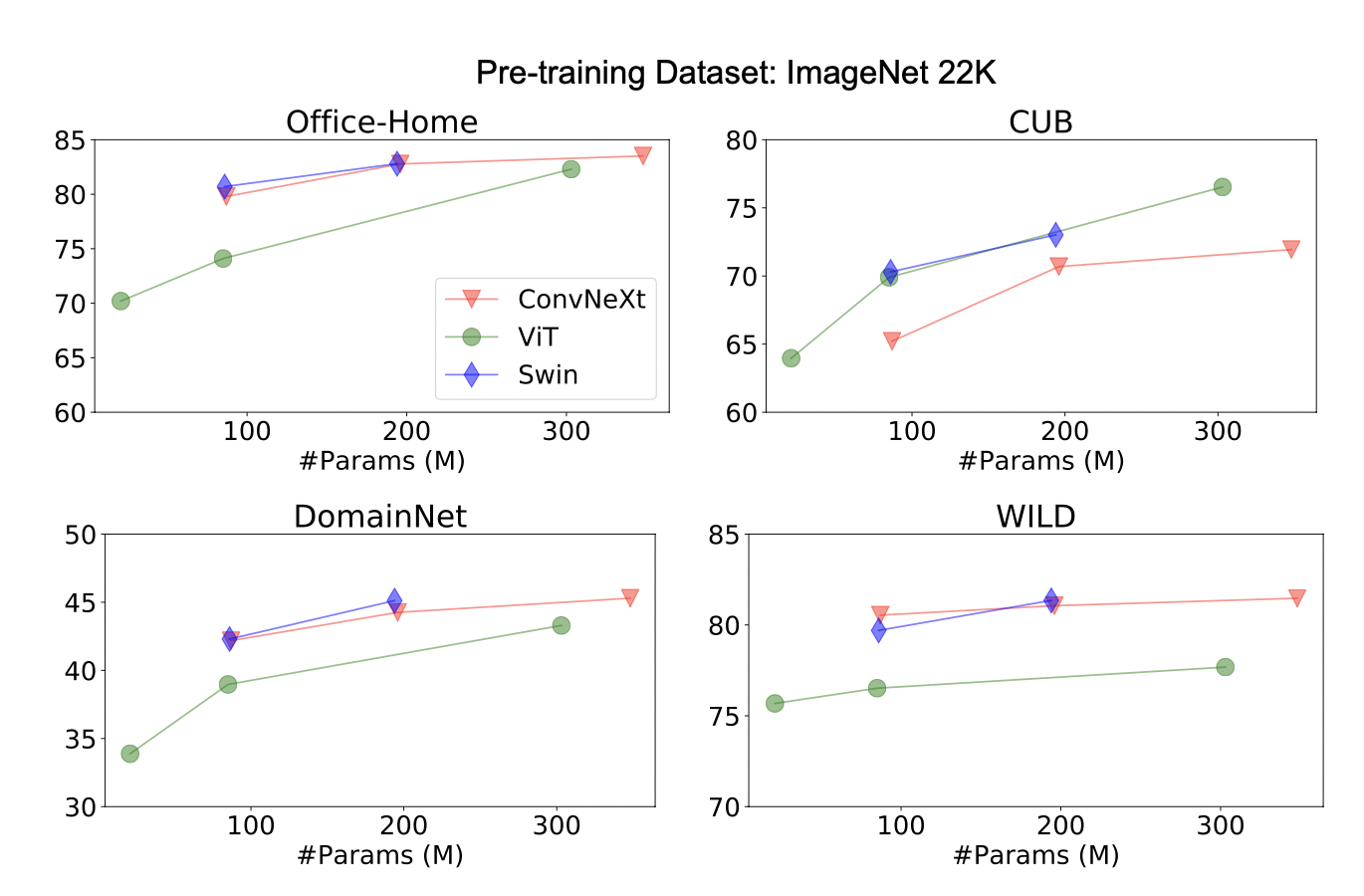
- Vit는 depth가 증가할 수록 성능 변화가 심함
- Swin, Convnext는 Vit에 비해 상대적으로 성능 변화가 적음
- shallow model을 통해 Adaptaion method의 성능을 비교할 때 Vit는 사용을 자제하는 것이 좋음
* Supervised vs. Self-supervised Learning
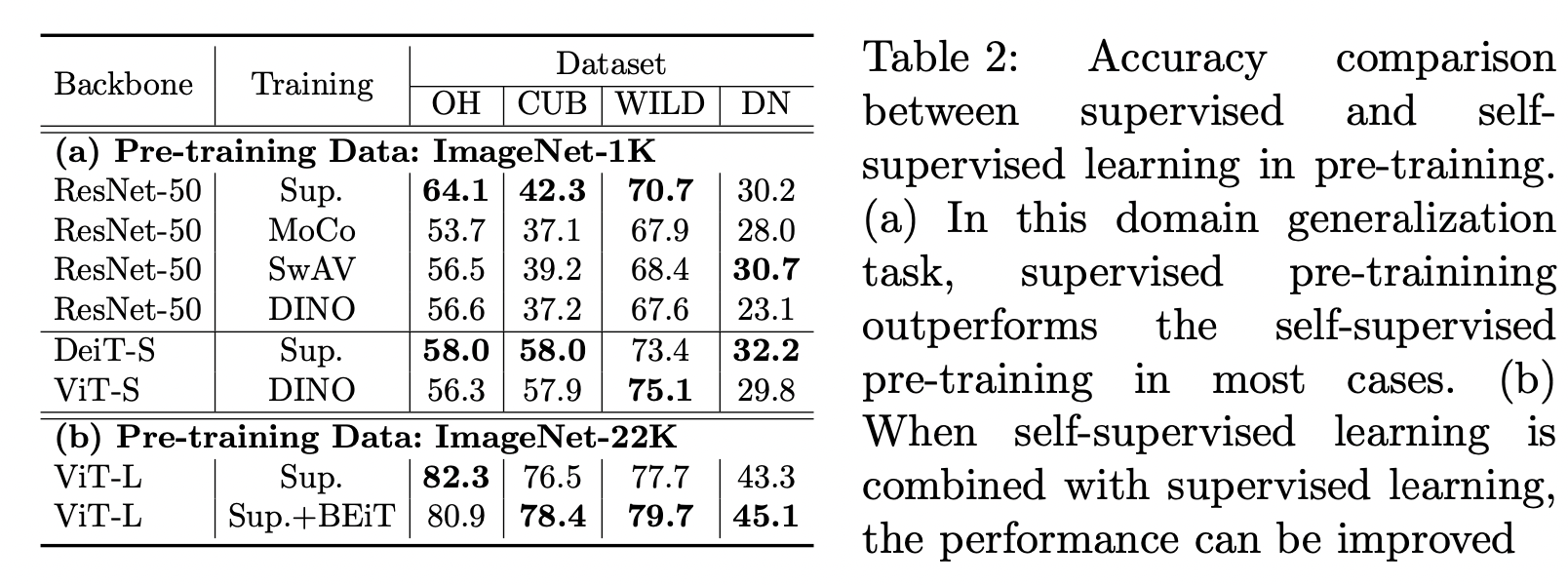
- 대부분 self-supervised 방식보다 supervised 방식이 더우 좋은 성능을 보임
- labeled data, unlabeled data를 함께 사용한 경우 성능을 더욱 끌어올릴 수 있음
* Comparison with Domain Adaptation Baselines
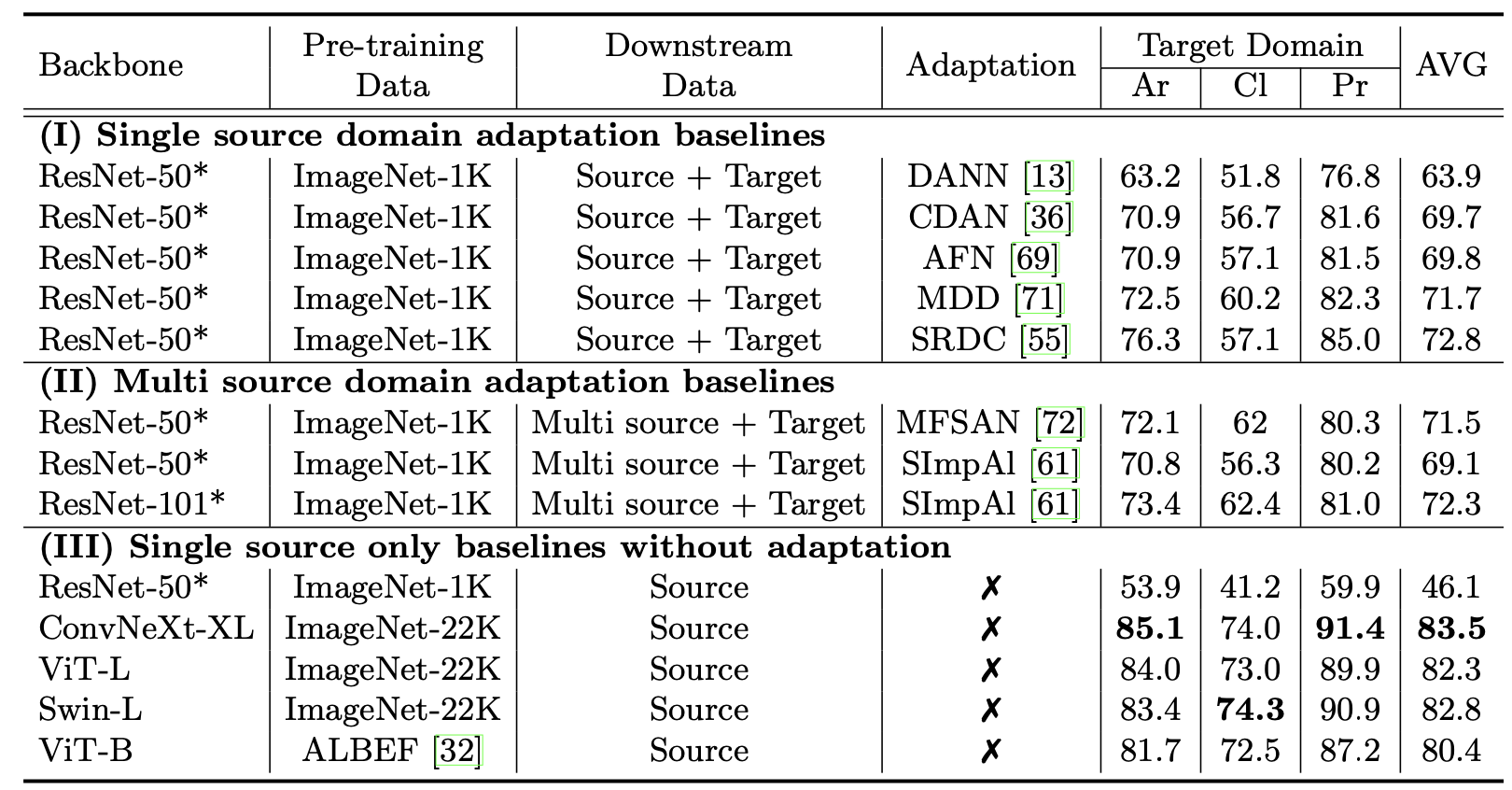
- 더욱 많은 데이터 셋을 통해 사전학습을 진행한 경우 adaptation을 진행한 경우보다 높은 성능을 보임
- ImageNet-1K 데이터 셋을 통해 사전학습된 ResNet을 adaptation method의 비교를 위한 표준으로 할 수 있을까? 의문
2) Domain Adaptation with Modern Pre-training
* Transferability of Domain Adaptation

- 최신 SOTA backbone에 대한 SOTA DA method 적용
- Real → Clipart(Cl) in Office-Home를 제외하고 DA method는 source 모델의 성능을 뛰어넘음
- 새로운 architecture에서 DA 방법의 rankinking은 달라짐
- adaptation methods는 새로운 architecture에 적용하기 위해 다양한 backbone에서 동일한 transferability를 가져야 함
3) Feature Analysis

- LogME가 높을 수록 feature transferability가 높음
- ResNet은 매우 낮은 feature transferability를 가짐
- CV의 발전에 따라 pre-training stage는 최신화 될 필요가 있음



