https://arxiv.org/abs/2112.03857
Grounded Language-Image Pre-training
This paper presents a grounded language-image pre-training (GLIP) model for learning object-level, language-aware, and semantic-rich visual representations. GLIP unifies object detection and phrase grounding for pre-training. The unification brings two ben
arxiv.org
(1) 배경
- visual recognition 모델은 사전에 추가적인 labeled data가 필요한 domain에 대한 generalization에는 약세를 보임
- clip은 image-text pair 를 학습하여 semantically rich 하고 다양한 downstream task에 사용될 수 있음
- object detection등의 task를 위해서는 fine-grained understanding of images 즉 object level의 visual representation의 이해가 필요함
--> phrase grounding은 phrases in a sentence, objects (or regions) in an image의 fine-grained correspondence를 식별
--> object level, language-aware, semantic-rich visual representation을 학습할 수 있음
--> phrase grounding과 object detection tasks를 모두 수행할 수 있는 방식인 Grounded Language-Image Pre-training (GLIP)을 제안
--> object detection 측면에서 grounding data를 통해 풍부한 visual concept를 학습할 수 있음
--> grounding 측면에서 더욱 많은 bounding box annotations을 제공받을 수 있음
(2) 방법
1) Unifying detection and grounding by reformulating object detection as phrase grounding
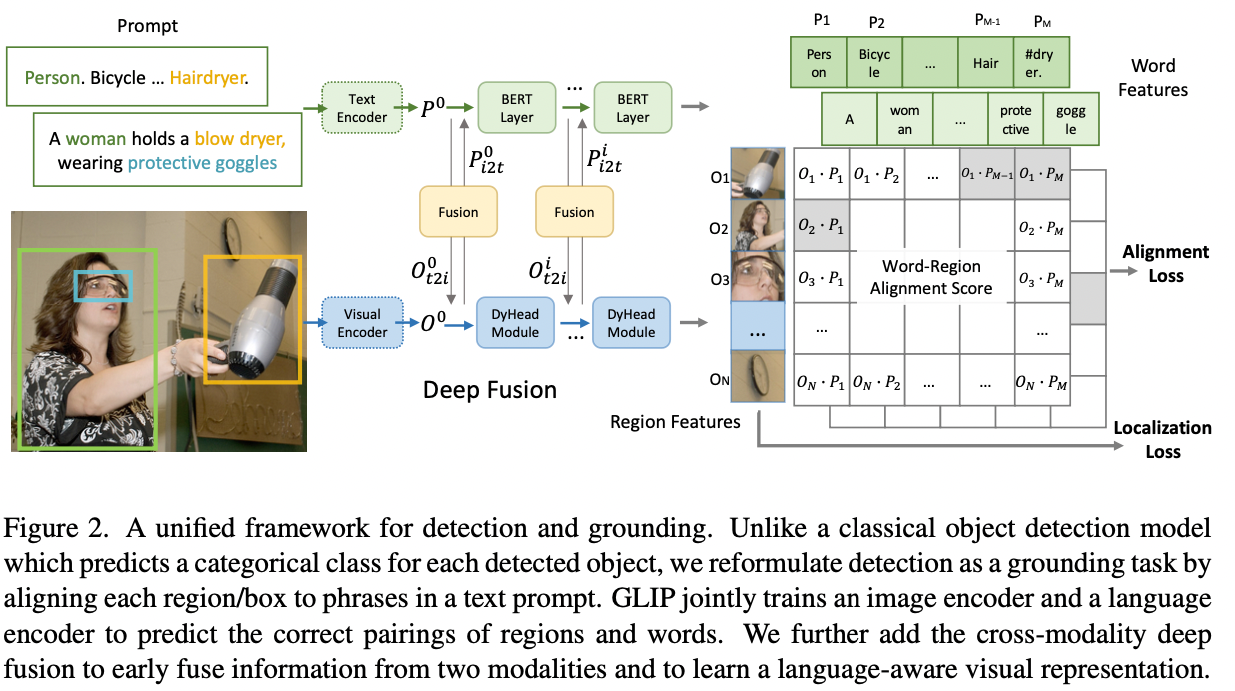
* Object detection as phrase grounding
- Prompt = “Detect: person, bicycle, car, ... , toothbrush" 로 정의

- 이미지와 prompt를 각각 Image encoder, Language encoder에 입력
- Region-word aligment scores를 image feature와 prompt feature의 dot product로 연산
- Region-word aligment scores에 대한 최종 Loss 연산 진행
--> 위 과정을 통해 detection을 grounding과 동일하게 진행할 수 있음
* Language-Aware Deep Fusion
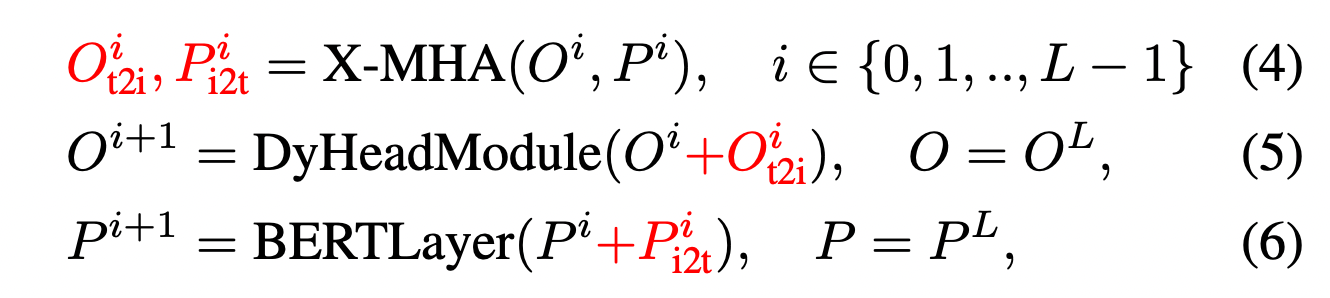
- 각각의 encoder에서 O(Image feature), P(Prompt feature)를 추출하고 cross-modality multi-head attention module (X-MHA)에 입력

- 이후 기존값에 X-MHA 출력값을 더해주고 single modality fusion 진행
- single modality fusion module은 각각 DyHeadModules in DyHead, BERTLayer 임
2) Pre-training with Scalable Semantic-Rich Data
- Teacher 모델을 통해 pseudo dataset을 생성할 수 있지만 concept pool 내에서만 활용 가능함.
- Glip은 detection data 뿐만 아니라 Grounding data를 함께 학습함
- gold grounding data는 기존 detection data보다 많은 vocabulary를 포함하고 있음
- detection data를 scaling up 하지 않고 grounding data를 scaling함
1. gold grounding data를 통해 teacher 모델 사전학습
2. web-collected image-text data에 대해 box를 예측하도록 함
3. gold data와 pseudo grounding data를 통해 student 모델 학습
(3) 실험 결과
1) Zero-Shot and Supervised Transfer on COCO

- Zero-shot Glip 모델은 SOTA 모델과 유사하거나 더욱 높은 성능을 보임
- GLIP-L은 최신 SOTA 성능을 뛰어넘음(Zero-shot X)
- Zero-shot 모델이 높은 성능을 보이는 이유
-- DyHead-T : Object365와 CoCo data는 서로 유사한 Domain을 가지고 있음 -- 이미 높은 성능을 보임
-- GLIP-T(A) : Grounding 모델로 개조함으로서 약간의 성능하락
-- GLIP-T(B) : Deep fusion layer를 추가해 약간의 성능 상승
-- GLIP-T(C) : gold grounding data를 통해 더욱 높은 성능을 얻음
-- GLIP-T : 추가적인 grounding data가 성능 상승에 영향을 주지 못함
2) Phrase Grounding on Flickr30K Entities
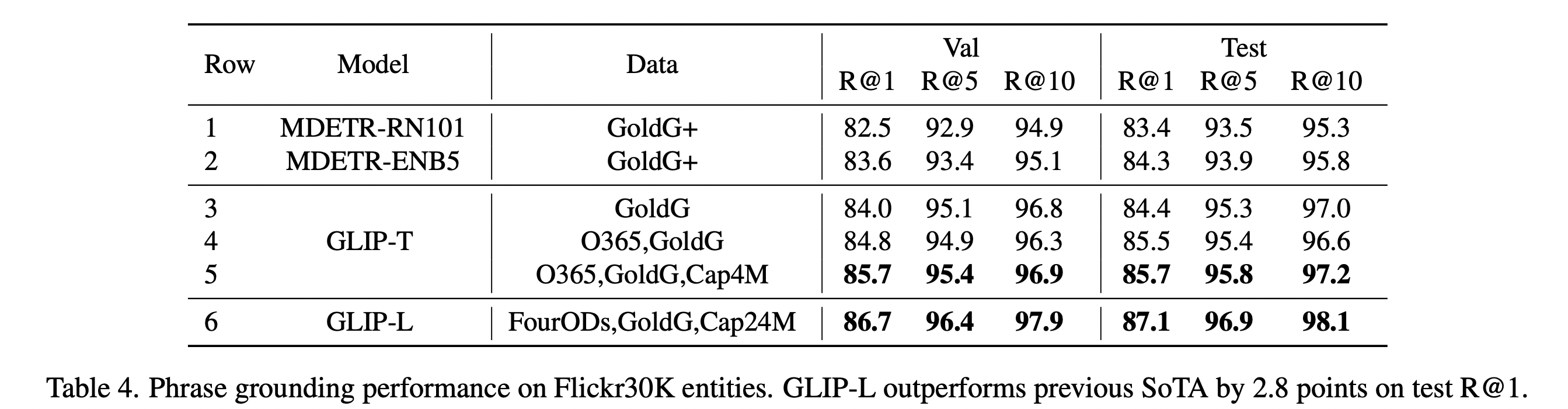
- MDETR은 Grounding 모델이며 GoldG+로만 학습됨
- Glip은 GoldG 만으로도 MDETR과 유사한 성능을 보이는데 이는 SwinTransformer, DyHead 도입에 의한 것으로 보임
- O365 detection dataset을 추가적으로 활용했을 때 성능 증가 --> Grounding + detection의 효과
3) Analysis

- 1 ~ 6 번줄을 보았을 때 detection dataset과 Grounding dataset을 함께 사용하는 것은 성능 증가에 도움을 줌
- 8번 줄은 2.66M 개의 detection data만 활용한 경우임 -> 6번 줄은 detection data 0.66M개, Grounding data 0.8M개만 사용했지만 더욱 높은 성능 달성
--> Grounding data 가 더욱 semantic-rich하고, detection data보다 더욱 scaling에 적합함


