1. Point-level supervision
우선 논문 리뷰 시작 전 Temporal action localiaztion(TAL)의 지도방식에 대해 우선 설명해 드리겠습니다.
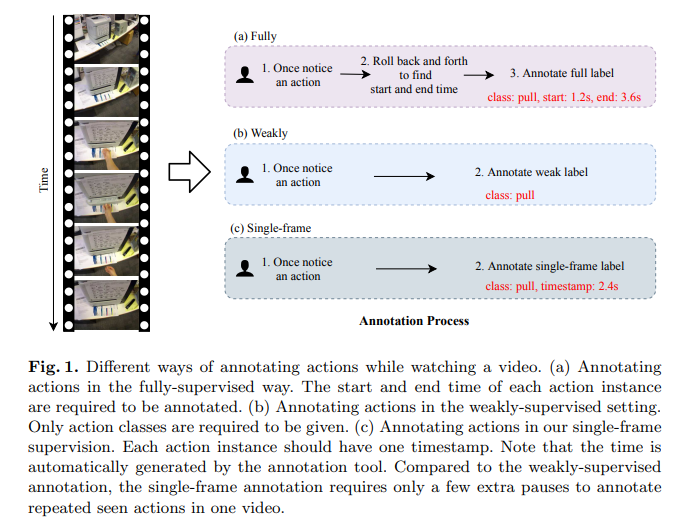
Fully-supervised TAL 은 action instance의 정확한 시작 시간 과 종료 시간을 제공해 주며, 이러한 정확한 annotaion을 제공받아 높은 성능을 달성합니다.
하지만 정확한 Annotation을 생성하기 위해 많은 시간과 노동력이 투입되어야 합니다.
이러한 문제를 해결하기위해 action class만을 annotation으로 모델에 제공하는 Weakly-supervised TAL이 제안 되었지만 제공되는 label이 너무 적어 성능이 매우 낮습니다.
이로 인해 최근에는 action에 속하는 frame의 위치 또는 시간을 action class와 함께 annotation으로 제공하는 Point-level supervised TAL이 등장하였습니다.
2. Introdution
LACP 모델은 single frame label을 통해 Temporal action localiaztion 문제를 해결하고자 고안하였습니다.
기존 방법은 label의 부족함으로 인해 action과 background를 구분하는 능력 즉 action completeness 학습에 실패하였습니다. .
이러한 문제를 해결하기 위해 위 논문에서는 2가지 새로운 방법을 제시합니다.
1. point supervised setting에서도 completeness guidance를 줄 수 있도록 optimal sequence를 찾는다.
2. score contrast loss, feature contrastive loss를 제안하였고 이를 통해 action과 background instances를 대조시켜 action completeness를 배울 수 있도록 한다.
3. Method
전체적인 모델 구조는 아래와 같습니다.
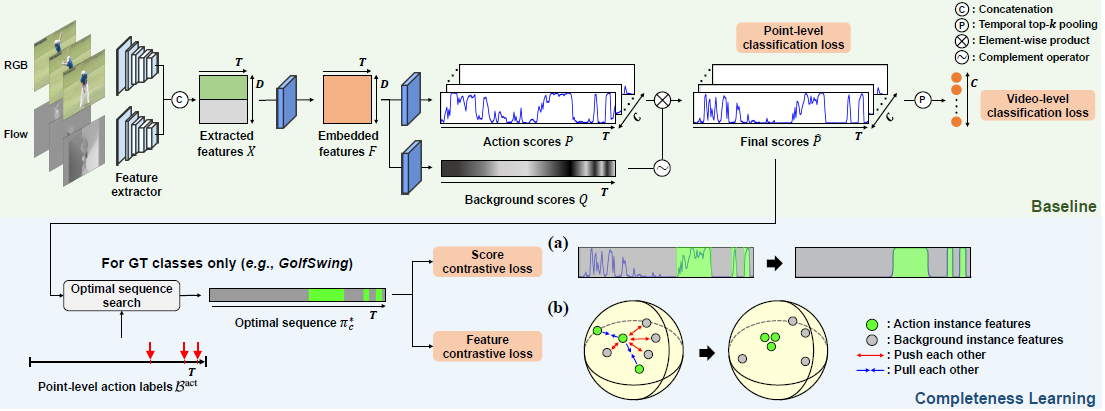
(1) Pseudo background point
서로 다른 2개의 action instance 사이에는 적어도 1개의 background point가 존재합니다.
우선 Threshold를 두어 action instance 사이의 background point를 선택합니다.
만약 아무 segment도 선택되지 않는다면 가장 높은 background score를 가지는 segment를 선택합니다.
(2) optimal sequence search
pseudo background point와 action point는 video의 일부분만 차지하며, 연속적이지 않습니다.
그래서 위 논문의 저자들은 매우 조밀한 pseudo point label을 발생시킵니다.
optimal sequence search를 통해 Fully supervised setting과 동일하게 모든 frame에 대한 annotation을 진행한다고 생각시면 됩니다.
더 간단히 말씀드리면 optimal sequence는 가짜 GT라고 생각하시면 됩니다.
action point과 pseudo background point를 통해 가능한 모든 sequence를 탐색합니다.
또한 optimal sequence의 completeness score를 측정하기 위해 outer-inner-contrast concept를 대용으로 사용합니다.
직관적으로 GT와 완벽히 일치하는 action instance는 contrast score가 높을 것입니다.
마지막으로 모든 action instance, background instance에 대해 contrast score을 계산하고 이를 평균 내어 completeness score의 대용으로 사용합니다.
아래는 optimal sequence search 전체 과정을 도식화한 것입니다.

(3) Score contrastive loss
score contrastive loss는 아래와 같습니다.
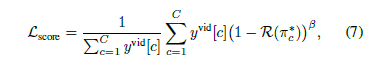
optimal sequence를 기준으로 action과 background를 구별하고 각각의 instance에 대한 contrast score를 계산합니다.
즉 모델의 output이 optimal sequence와 일치할수록 Loss는 작아지게 됩니다.
(4) Feature contrastive loss

optimal sequence를 기준으로 action instance와 background instance에서 feature를 추출합니다.
action instance의 feature과 background instance의 feature은 서로 달라야 합니다.
위의 Feature contrastive loss는 action instance와 action instance의 feature가 유사해질수록, background instance와 feature 대조가 점점 심해질수록 작아집니다.
4. Experiments
(1) Quantitative results
TAD SOTA 모델과 위 논문에서 제안하는 모델과의 성능 비교입니다.
다른 지도 방식을 가지는 TAD 모델과도 비교를 진행하였습니다.
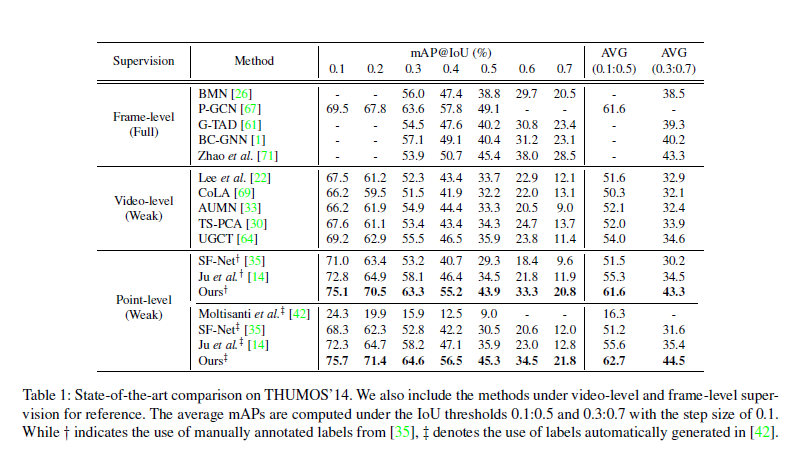
point-supervised 방식에서의 결과를 보시면 기존 방식에 비해 매우 높은 성능을 보임을 알 수 있습니다.
또한 합리적인 labeling cost를 가지면서 weakly-supervised models에 비해 매우 높은 성능을 보입니다.
또한 fully-supervised models보다 적은 annotaion 정보가 주어짐에도 fully-supervised models와 대등한 성능을 기록하기도 합니다.
하지만 action과 boundary의 경계에 대한 정보가 매우 적기 때문에 높은 tIOU threshold에서는 성능이 크게 저하됩니다.
(2) Qualitative results
아래는 기존 point-supervised 방식의 모델인 SF-Net과의 정성적인 비교를 보여줍니다.

왼쪽 그림에서 SF-Net은 부분적인 action instance 예측만을 보여주고, 오른쪽 그림은 GT보다 더 넓은 공간에 대해 예측을 하였습니다.
하지만 위 논문에서 제안하는 방법은 GT와 거의 유사한 action instance를 예측하였습니다.
5. Conclusion
위 논문은 Point-level supervised TAL 을 위한 새로운 프래임 워크를 제안하였습니다.
주어진 point label을 통해 optimal sequence를 찾았으며 이를 통해 score contrast loss, feature contrastive loss를 계산하였고 action conpleteness를 학습하는 데 성공하였습니다.



