1. 가상환경 설정
1) ResolvePackageNotFound:
- conda env export 명령어는 현재 환경의 패키지 목록과 버전을 파일로 내보내어 다른 환경에서 재현할 수 있도록함
- > export된 환경 파일은 호스트 환경의 차이로 인해 다른 환경에서 작동하지 않을 수 있음
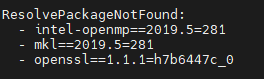
- environment.yml 파일을 열어 아래와 같이 수정해주면 해결됨
| - intel-openmp - mkl - openssl==1.1.1 |
| conda env create -f environment.yml conda activate m2release pip install spacy python -m spacy download en_core_web_sm |
2. Training
(1) 데이터 준비
1) 데이터 다운로드
- X-101-features.tgz를 논문 저자 github 링크에서 찾아가 다운받음
- float16으로 저장하는 과정에서 아래 오류 발생
| python switch_datatype.py |
- AttributeError: 'Namespace' object has no attribute 'dir_to_save_feats'. Did you mean: 'dir_to_raw_feats'?

- switch_datatype.py를 열어보며 main함수에서 dir_to_save_feats은 feature 가 저장된 파일 dir_to_save_float16_feats은 float16으로변환 후 저장할 파일 위치를 말하는 것으로 보임
- 하지만 parser 인자를 보면 dir_to_raw_feats와 dir_to_float16_feats가 있음
-> dir_to_raw_feats => dir_to_save_feats, dir_to_float16_feats => dir_to_save_float16_feats로 수정
아래는 수정한 코드이다.
# switch data from float32 to float16
import os
import torch
from tqdm import tqdm
import numpy as np
import argparse
def main(args):
data_splits = os.listdir(args.dir_to_save_feats)
for data_split in data_splits:
print('processing {} ...'.format(data_split))
if not os.path.exists(os.path.join(args.dir_to_save_float16_feats, data_split)):
os.mkdir(os.path.join(args.dir_to_save_float16_feats, data_split))
feat_dir = os.path.join(args.dir_to_save_feats, data_split)
file_names = os.listdir(feat_dir)
print(len(file_names))
for i in tqdm(range(len(file_names))):
file_name = file_names[i]
file_path = os.path.join(args.dir_to_save_feats, data_split, file_name)
data32 = torch.load(file_path).numpy().squeeze()
data16 = data32.astype('float16')
image_id = int(file_name.split('.')[0])
saved_file_path = os.path.join(args.dir_to_save_float16_feats, data_split, str(image_id)+'.npy')
np.save(saved_file_path, data16)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='swith the data type of features')
parser.add_argument('--dir_to_save_feats', type=str, default='./Datasets/X101-features/', help='big data')
parser.add_argument('--dir_to_save_float16_feats', type=str, default='./Datasets/X101-features-float16', help='little data')
args = parser.parse_args()
main(args)
- feat_process.py 실행
| python feats_process.py |
- 현재 feature는 npy 파일로 수정되어 있으며 torch.load()를 통해 불러올 수 없음
-> 아래와 같이 코드를 수정해 주어야 함
import os
import h5py
import argparse
import torch
import torch.nn as nn
import json
from tqdm import tqdm
import numpy as np
class DataProcessor(nn.Module):
def __init__(self):
super(DataProcessor, self).__init__()
self.pool = nn.AdaptiveAvgPool2d((7, 7))
def forward(self, x):
x = self.pool(x)
x = torch.squeeze(x) # [1, d, h, w] => [d, h, w]
x = x.permute(1, 2, 0) # [d, h, w] => [h, w, d]
return x.view(-1, x.size(-1)) # [h*w, d]
def process_dataset(file_path, feat_paths):
print('save the ori grid features to the features with specified size')
# 加载特征处理器
processor = DataProcessor()
with h5py.File(file_path, 'w') as f:
for i in tqdm(range(len(feat_paths))):
# 加载特征
feat_path = feat_paths[i]
############################################################ numpy -> torch
img_feat = np.load(feat_path)
# 处理特征
img_feat = torch.from_numpy(img_feat.astype(float))
############################################################
img_feat = processor(img_feat)
# 保存特征
img_name = feat_path.split('/')[-1]
img_id = int(img_name.split('.')[0])
f.create_dataset('%d_grids' % img_id, data=img_feat.numpy())
f.close()
def get_feat_paths(dir_to_save_feats, data_split='trainval', test2014_info_path=None):
print('get the paths of raw grid features')
ans = []
# 线下训练和测试
if data_split == 'trainval':
filenames_train = os.listdir(os.path.join(dir_to_save_feats, 'train2014'))
ans_train = [os.path.join(dir_to_save_feats, 'train2014', filename) for filename in filenames_train]
filenames_val = os.listdir(os.path.join(dir_to_save_feats, 'val2014'))
ans_val = [os.path.join(dir_to_save_feats, 'val2014', filename) for filename in filenames_val]
ans = ans_train + ans_val
# 线上测试
elif data_split == 'test':
assert test2014_info_path is not None
with open(test2014_info_path, 'r') as f:
test2014_info = json.load(f)
for image in test2014_info['images']:
img_id = image['id']
########################################################################### pth -> npy
feat_path = os.path.join(dir_to_save_feats, 'test2015', str(img_id) + '.npy')
###########################################################################
# assert os.path.exists(feat_path)
ans.append(feat_path)
assert len(ans) == 40775
# assert not ans # make sure ans list is not empty
return ans
def main(args):
# 加载原始特征的绝对路径
feat_paths = get_feat_paths(args.dir_to_raw_feats, args.data_split, args.test2014_info_path)
# 构建处理后特征的文件名和保存路径
file_path = os.path.join(args.dir_to_processed_feats, 'X101_grid_feats_coco_'+args.data_split+'.hdf5')
# 处理特征并保存
process_dataset(file_path, feat_paths)
print('finished!')
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='data process')
parser.add_argument('--dir_to_raw_feats', type=str, default='./Datasets/X101-features-float16/')
parser.add_argument('--dir_to_processed_feats', type=str, default='./Datasets/feature')
# trainval = train2014 + val2014,用于训练和线下测试,test = test2014,用于线上测试
parser.add_argument('--data_split', type=str, default='test') # trainval, test
# test2015包含test2014,获取test2014时,先加载test2014索引再加载特征,image_info_test2014.json是保存test2014信息的文件
parser.add_argument('--test2014_info_path', type=str, default='./m2_annotations/image_info_test2014.json')
args = parser.parse_args()
main(args)
(2) Train
1) BERT-based language model 학습
| python train_language.py --exp_name bert_language --batch_size 50 --features_path /path/to/features --annotation_folder /path/to/annotations |
- OSError: [E050] Can't find model 'en' 오류 발생

- > spacy 모듈을 사용할 때 언어 모델을 설치하지 않아 발생
| python -m spacy download en |
2) train RSTNet model
- language 모델 경로를 TransformerDecodeLayer에 입력해 주어야함

- train
| python train_transformer.py --exp_name rstnet --batch_size 50 --m 40 --head 8 --features_path /mnt/HDD1/HW_2/RSTNet/Datasets/feature/X101_grid_feats_coco_trainval.hdf5 --annotation_folder ./m2_annotations |
- RuntimeError: gather(): Expected dtype int64 for index 오류 발생

이외 수많은 오류 발생.. 모든 것을 적기에는 힘듬
3. 결과
| Metrics Model |
B@1 | B@4 | METEOR | ROUGE | CIDEr |
| RSTNet (Table4) | 0.811 | 0.393 | 0.294 | 0.588 | 1.333 |
| RSTNet (재현) | 0.813 | 0.399 | 0.289 | 0.590 | 1.302 |
4. 참고 문헌
[1] Yoo, Jaejun and Ahn, Namhyuk and Sohn, Kyung-Ah, "Rethinking Data Augmentation for Image Super-resolution: A Comprehensive Analysis and a New Strategy, "arXiv preprint arXiv:2004.00448, 2020



