위 논문에서 제안한 Hybrid Attention Transformer(HAT) 모델은 channel attention과 window-based self attention을 결합한 최근 Single Image Super Resolution(SISR) Sota를 달성하였습니다.
(1) 동기
최근 Transformer 기반의 방법은 low-level vision task에서 상당한 성과를 보여주었습니다.
하지만 Transformer 기반의 방법이 왜 CNN architecture에 기반한 모델보다 뛰어난 성능을 보이는지는 명확하지 않습니다.
우리는 그저 self-attention mechanism과 long-range information을 활용해서 더 뛰어난 것이라고 직관적으로 설명하고 있습니다.
그래서 위 논문의 저자들은 속성 분석 방법인 LAM을 도입해 swinIR(Transformer 기반의 방법)이 이미지를 재구성하기 위해 어느 정도 범위의 정보를 활용하는지 분석합니다.
여기서 LAM은 integral gradient 방법을 사용하며 어떠한 input pixel이 최종 결과에 기여하는가 연구하기 위해 제안된 방법입니다.

위 그림은 서로 다른 모델에 대한 LAM의 결과를 나타냅니다.
빨간점은 Low Resolution(LR) 이미지에서 High Resolution(HR)이미지의 빨간 박스 영역을 생성하기 위해 활용한 pixel 입니다.
여기서 EDSR과 RCAN은 CNN 기반의 모델이며 SwinIR와 HAT은 Transformer 기반의 모델입니다.
EDSR과 RCAN을 보았을 때 RCAN이 더 많은 pixel을 활용하고 있으며 이를 통해 EDSR에 비해 높은 성능을 달성합니다.
하지만 SwinIR이 RCAN보다 더 적은 pixel을 활용하기 있음에도 불구하고 더욱 높은 성능을 보이고 있습니다.
이는 Transformer기반의 방식이 CNN 기반의 방식보고 더욱 강력한 mapping 능력을 가지고 있다는 것을 의미하며 이를 통해 더 적은 정보를 활용해 더 좋은 성능을 달성할 수 있습니다.
하지만 한정된 영역의 정보만을 활용하여 잘못된 texture를 생성할 수도 있습니다.
이를 통해 위 논문의 저자는 만약 Transformer기반의 방식이 input pixel을 더욱 활용한다면 더욱 높은 성능을 달성할 수 있을 것이라 생각하였습니다.

위 그림은 SwinIR의 중간 단계에서 관찰된 blocking artifacts입니다.
이러한 artifact는 window partition mechanism에 의해 나타나며, shift-window mechanism만으로 cross-window connection을 구축하기는 부족하다는 것을 나타냅니다.
즉 shift-window mechanism은 window간의 상호작용이 부족하며, 이를 강화하기 위한 모델 디자인이 필요하다고 합니다.
(2) 제안하는 방법
1) Channel Attention Block (CAB)

CAB는 Residual block과 Channel Attention으로 구성되어 있습니다.
우선 Residual block은 pixel값의 범위의 유연성을 위해 ResNet의 구조에서 Batch Normalization을 제거하였습니다.
Channel Attention은 network가 더욱 중요한 feature에 집중하기 위해 사용하며 channel 사이의 상호 의존성을 이용합니다.

마지막으로 CAB는 위 그림과 같이 Swin transformer의 window-based multi-head self-attention (W-MSA)과 병렬로 연산을 진행하고 결합합니다.
2) Overlapping Cross-Attention Block(OCAB)
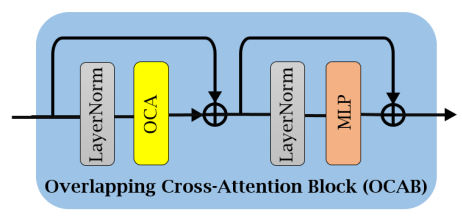
OCAB는 위와 같이 Overlapping Cross-Attention layer와 MLP layer로 이루어져 있으며 Swin Transformer와 유사합니다.

OCA에서 query(Q)는기존 Swin Transformer의 window partition과 동일하게 겹치지 않게 window를 나누고 생성합니다.
이와 달리 key(K)와 value(V)는 window partition을 진행할 때 이 window들이 서로 겹쳐져 있습니다.
기존의 WSA는 Q,K,V를 동일한 window feature에서 추출하였지만 OCA에서는 K,V를 더욱 넓은 영역에서 추출하고, 이영역을 통해 Q에 더 유용한 정보를 제공합니다.
3) Same-task Pre-training Strategy
위 논문의 저자들은 ImageNet을 통해 HAT에 대한 사전학습을 진행합니다.
만약 X4SR을 위한 모델이라면 X4 SR모델을 ImageNet을 통해 사전학습을 진행하고, DF2K 데이터 셋을 통해 파인 튜닝을 진행합니다.
사전학습 단계에서 충분한 iteration을 반복해야하며, 파인 튜닝을 진행할 때 학습률을 낮추어 주어야 합니다.
(3) 결과
1) OCAB and CAB

위 표와 그림은 OCAB, CAB를 적용한 결과를 보여 줍니다.
OCAB를 적용하였을 경우 우선 그림에서 볼 수 있듯이 OCAB를 적용하지 않았을 때보다 더욱 많은 input pixel을 활용하고 있으며 이를 통해 PSNR이 0.1 상승하였습니다.
CAB를 적용하였을 경우에도 CAB를 적용하지 않았을 때 보다 더욱 많은 input pixel을 활용하고 있으며 이를 통해 PSNR이 0.1 상승하였습니다.
또한 이 둘을 함께 사용하였을 경우 input pixel을 대부분 활용하고 있으며 성능이 크게 상승하였습니다.
2) Quantitative results
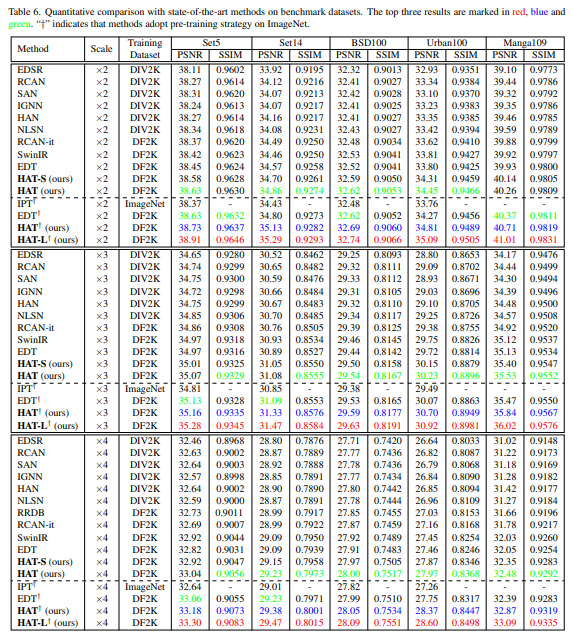
위 결과는 HAT 모델을 DF2K로 학습하고 5개의 Benchmark dataset에 대해 평가한 결과입니다.
또한 †로 표시된 것은 ImageNet으로 사전학습을 진행하고 DF2K 데이터 셋으로 파인튜닝한 결과를 나타냅니다.
DF2K로 학습을 진행하였을 경우 이전의 방법에 비해 상당히 높은 성능을 기록하였습니다.
또한 사전학습을 진행한 경우 더욱 높은 성능 상승을 이루었으며 이전 방법과 비교해서도 상당한 차이를 보입니다.
3) 요약
1. self-attentino machanism을 사용하며 더욱 많은 input pixel을 활용하기위해 channel attention과 window-based self attention을 결합
2. blocking artifacts를 제거하기 위해 overlapping cross-attention module을 제안
3. 모델의 잠재력을 극재화 하기 위해 same-task pre-training을 제안
4. 기존의 sota 방법들에 비해 1dB 뛰어난 모델을 개발함



